DPA4 Tops Matbench Discovery: A Single RTX 5090 Delivers SOTA-Level Large Atomic Models in One Day
Recently, the OpenLAM Team of the Beijing Academy of AISI, Peking University, DeepModeling Technology, and the Institute of Applied Physics and Computational Mathematics have jointly launched DPA4, a new-generation model architecture tailored for the era of Large Atomic Models (LAMs). DPA4 claimed the top spot worldwide with its comprehensive performance score (CPS) on Matbench Discovery, an authoritative global benchmark for materials discovery, emerging as the latest State-of-the-Art (SOTA) model.
DPA4’s highlight lies in its ultra-low training threshold: the prior leading eSEN needed over 300 GPU days for training, yet DPA4 reaches matching accuracy with merely one consumer RTX 5090 running for roughly one day, and its parameter volume is less than one-tenth of eSEN’s.
In short, the SOTA-level accuracy once reliant on costly supercomputing is now accessible via a single consumer graphics card. DPA4 reshapes the accuracy-efficiency Pareto frontier of large atomic models.
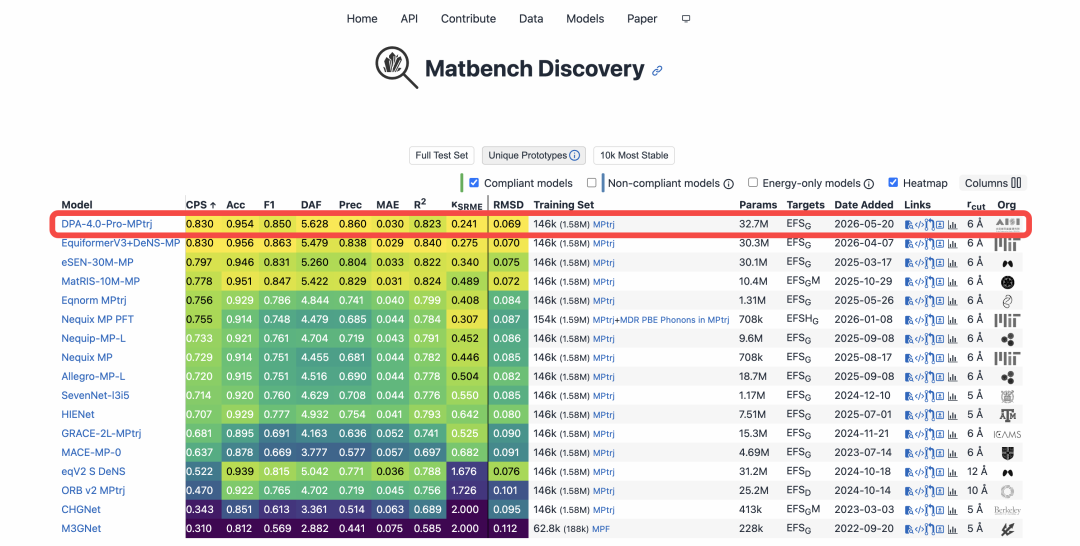
Official Screenshot of Matbench Discovery (Data as of May 22, 2026)
DPA4 adopts SO(2) equivariant linear operators paired with local-coordinate attention. It satisfies translation, rotation, permutation symmetries and energy conservation while cutting equivariant computation costs drastically. It also pioneers global compile-accelerated training for machine learning potentials, lifting training speed 2–3 times. It secured SOTA top rankings on two key benchmarks: Matbench Discovery and SPICE-MACE-OFF. It strikes a new balance of precision and training cost: a single RTX 5090 trains it in one day to match eSEN’s 300+ GPU-day accuracy; parameters are under 1/10 of eSEN; versus its predecessor DPA3, training efficiency is about 10x higher at equal accuracy.
DPA4 early access is open to the DeepModeling community. Its research paper and full official code will be open-sourced later; readers may join the article’s ending WeChat group for academic exchanges. Below is a condensed technical introduction.
1. DPA4 Model Architecture: SO(2) Equivariant Design in Local Coordinate Systems
Traditionally, SO(3) equivariant models rely on complex Clebsch–Gordan tensor products to retain rotational symmetry, whose computational complexity spikes sharply [about $$O(l_{max}^6)$$] with the increase of angular momentum order $$l_{max}$$— this is the core reason high-precision models demand massive computing resources.
DPA4’s core idea avoids expensive global SO(3) tensor calculations by simplifying symmetry processing to the SO(2) subgroup: it builds a local coordinate frame for each atomic bond, unifying bond orientations to a reference axis. Axial rotation symmetry only requires SO(2) processing, whose simple block-structured linear mappings replace heavy SO(3) tensor operations. Full rotational equivariance is preserved while angular computation overhead drops greatly.
On this basis, DPA4 further incorporates attention mechanisms to aggregate information from neighboring atoms. The model can adaptively focus on the most critical atomic interactions for the central atom according to local geometric and chemical environments, thus delivering strong expressive power with a compact parameter scale. The entire model strictly adheres to translation, rotation, permutation symmetries and energy conservation, ensuring full physical consistency.
Two major engineering optimizations further lift efficiency:
- Native torch.compile compatibility: end-to-end acceleration without extra code edits
- Embedded ZBL short-range repulsive potential: stabilizes simulations under high pressure, irradiation, defects and other extreme atomic configurations
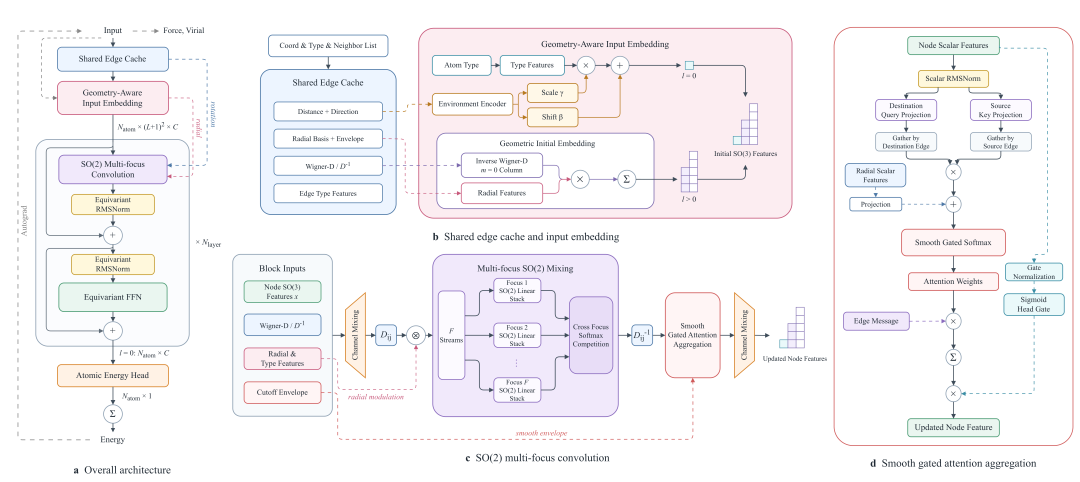
DPA4 Model Structure Diagram
2. Benchmark Performance: Dual No.1 Titles
Matbench Discovery: Global Champion for Materials Discovery. Launched by UC Berkeley, Cambridge University and other top institutes, Matbench Discovery is the world’s leading dynamic benchmark for AI inorganic material prediction, widely accepted as the industry gold standard. Instead of static data fitting, it tests model capacity to forecast stability of hundreds of thousands of unknown crystals, mimicking real exploratory research. Final Comprehensive Performance Score (CPS) integrates energy/force accuracy, F1 score and discovery acceleration factors. Beating SOTA models from Meta, Microsoft and global universities, DPA4 claimed the top CPS rank.
SPICE-MACE-OFF: Top Small-Molecule Performance. DPA4 excels beyond inorganic crystals, setting a new SOTA record on the SPICE-MACE-OFF small-molecule benchmark. With smaller parameter size, it outperformed the former leading model eSEN to take the first place, proving its versatility as a universal potential energy surface model for crystals and organic small molecules alike.
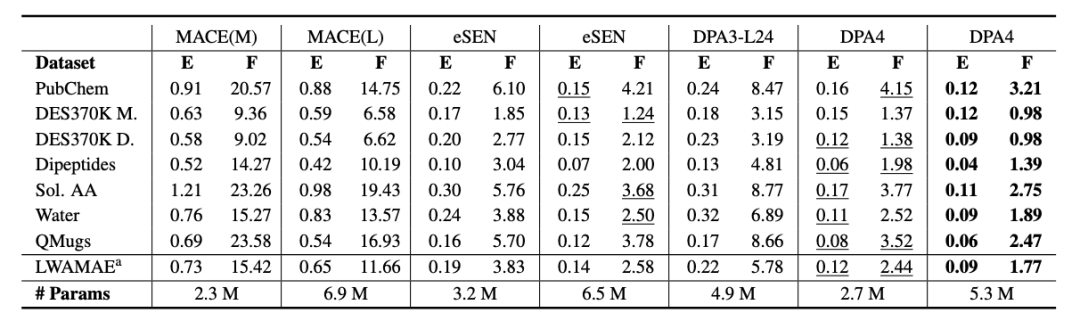
Performance on SPICE-MACE-OFF
3. Efficiency Breakthrough: A New Precision-Cost Pareto Frontier
Top benchmark results confirm DPA4’s outstanding accuracy, yet its revolutionary value lies in minimal training cost. Conventional leading models always require larger parameters and heavier computation; DPA4 breaks this norm:
- Training cost: 1 RTX 5090 (~1 day) = eSEN’s 300+ GPU days of precision
- Parameter scale: <1/10 of eSEN at equivalent CPS
- Generation upgrade: ~10× training efficiency vs DPA3 under equal prediction accuracy
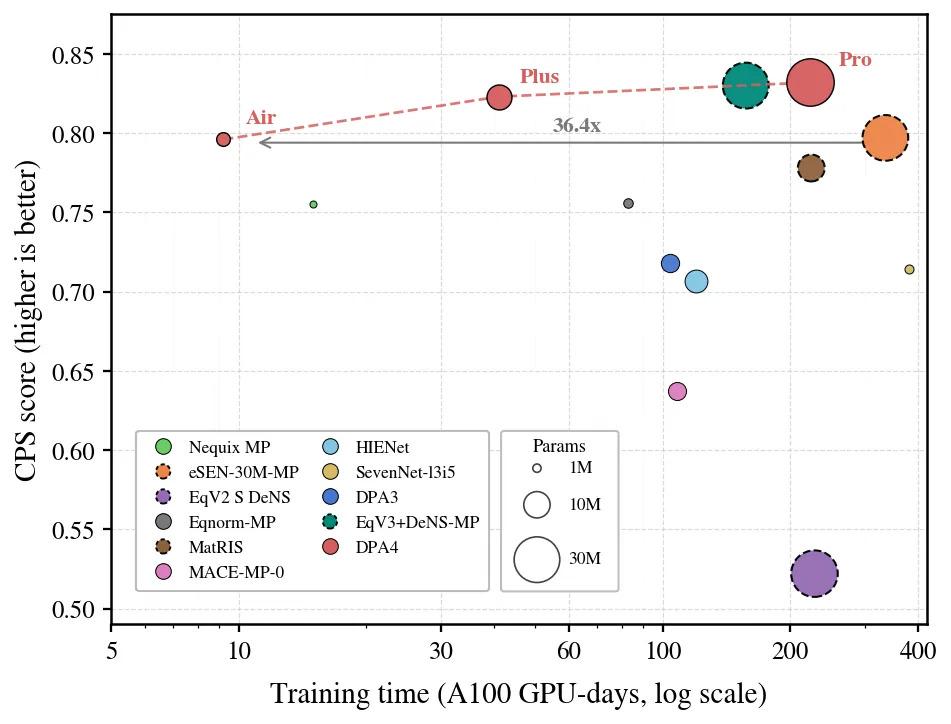
DPA4 Redefining the Accuracy-Efficiency Pareto Frontier for Large Atomic Models
Multi-layer engineering optimizations enable such efficiency gains. Unlike standard AI models, potential training needs double backward calculation for force derivation, which long blocked torch.compile use and forced large batch sizes to boost GPU utilization. DPA4 is the world’s first machine learning potential supporting compile training. Paired with bf16 automatic mixed precision (AMP), it slashes VRAM usage drastically, enabling full training on a single graphics card.

Comparison of Training Time and Peak Video Memory Usage with DPA4’s Compile and AMP Enabled
This breakthrough accelerates model iteration for researchers; fixed computing budgets support larger-scale, longer-time microscopic simulations. DPA4 turns high-throughput atomic simulation from a high-cost luxury into accessible tools, supporting battery material R&D, catalyst design, semiconductor screening and other key industries.
Summary
DPA4 is a universal next-gen potential framework for the LAM era. Its local SO(2) equivariant operators plus attention maintain physical consistency while cutting computation costs; native compile acceleration and built-in ZBL potential further boost engineering performance.
It claimed dual top benchmark rankings, delivering matching or superior precision to prior costly large models with <1/10 parameters and one-day single-GPU training. DPA4 verifies high accuracy and high efficiency can be achieved simultaneously.
Early access is open to DeepModeling community members; papers and full open-source code will be released sequentially later. The team sticks to open collaboration in LAM research, inviting global scholars to follow progress and join the community.
Core Developers & Affiliated Institutions
Li Tiancheng (Peking University, AISI)
Xue Jianming (Peking University)
Zhang Linfeng (DP Technology, AISI)
Zhang Duo (Peking University, AISI)
Wang Han (Institute of Applied Physics and Computational Mathematics)